Django 6.0 introduces a built-in background tasks framework in django.tasks. But don't expect to phase out Celery, Huey or other preferred solutions just yet.
The release notes are quite clear on this:
Django handles task creation and queuing, but does not provide a worker mechanism to run tasks. Execution must be managed by external infrastructure, such as a separate process or service.
The main purpose of the new django.tasks module is to provide a common API for task queues implementations. Jake Howard is the driving force behind this enhancement. Check out the introduction on the Django forum.
His reference implementation, and simultaneously a backport for earlier versions of Django, is available as django-tasks on GitHub.
But let's ignore that and play with the more minimal version included in Django 6.0 instead. By creating our very own backend and worker.
Our project: notifications
We're going to create an app to send notifications to phones and other devices using ntfy.sh. (I'm a fan!)
If you prefer to dive into the code yourself, check out the final version of the project on GitHub.
All that's required to send a notification to your phone using nfty is:
- Register for an account
- Create a topic.
- Install the app for your phone and log in.
- Send HTTP requests to
https://ntfy.sh/<yourtopic>
The free version only provides public topics and messages. Meaning anyone can see the stuff you're sending if they subscribe to the topic. For our purpose we can simply create a topic with a randomized name, like a UUID.
The project's settings expect the URL from step 4 to be supplied as an environment variable. For example:
NTFY_URL=https://ntfy.sh/062519693d9c4913826f0a39aeea8a4c
Here's our function that does the heavy lifting:
import httpx
from django.conf import settings
def send_notification(message: str, title: str | None):
# Pass the title if specified.
headers = {"title": title} if title else {}
httpx.post(
settings.NTFY_URL,
content=message,
headers=headers,
)
Really. That's all there is to it to start sending and receiving notifications.
A quick primer
You really should have a look at the Django documentation on the Task framework for details, but we'll save you a bit of time and give a quick primer.
Defining a task
This is the main goal of the new framework: defining tasks using Django's standard API, rather than using task queue specific decorators, or other methods.
So here it goes:
# ...
from django.tasks import task
@task
def send_notification(message: str, title: str | None):
# ...as before
Our function is now a task. In fact it's a django.tasks.Task.
You cannot call send_notification directly anymore. Tasks can only be run by using the enqueue method. It might not be the behavior you'd expect or want, but this seems to be the best option. This design eliminates the possibility of accidentally invoking a task in-process, rather than in the background.
The task decorator allows you to specify the task's priority, queue name and backend name. You can override these settings with the using method, which returns a new django.tasks.Task instance.
If you need more control over task behavior, you can set takes_context to True in the decorator and add context as the first argument. This context currently provides you with access to the task result and thereby useful information like the number of attempts.
There's no way of defining retries and backoffs, or other fancy things you might expect from a full-blown task queue implementation. But that's not what this is. You can easily add your own retry logic by inspecting the task context if needed.
Enqueuing a task
Adding a task to the queue is easy:
task_result = send_notification.enqueue(
message="Season's greeting!",
title="Santa has something to tell you"
)
Executing a task
This is where things start to fall short. At least right now. Django 6.0 will ship with the ImmediateBackend and the DummyBackend. The first will execute the task immediately, while the latter will not execute the task at all.
Which is why our project includes a (demo) backend backed by the database and a worker process!
Fetching the result
If you're not going to wait around for the result, you can get a hold of it later on using its id. Simply call get_result(result_id) on your task.
Our project includes a view that's polled periodically for outstanding results using htmx.
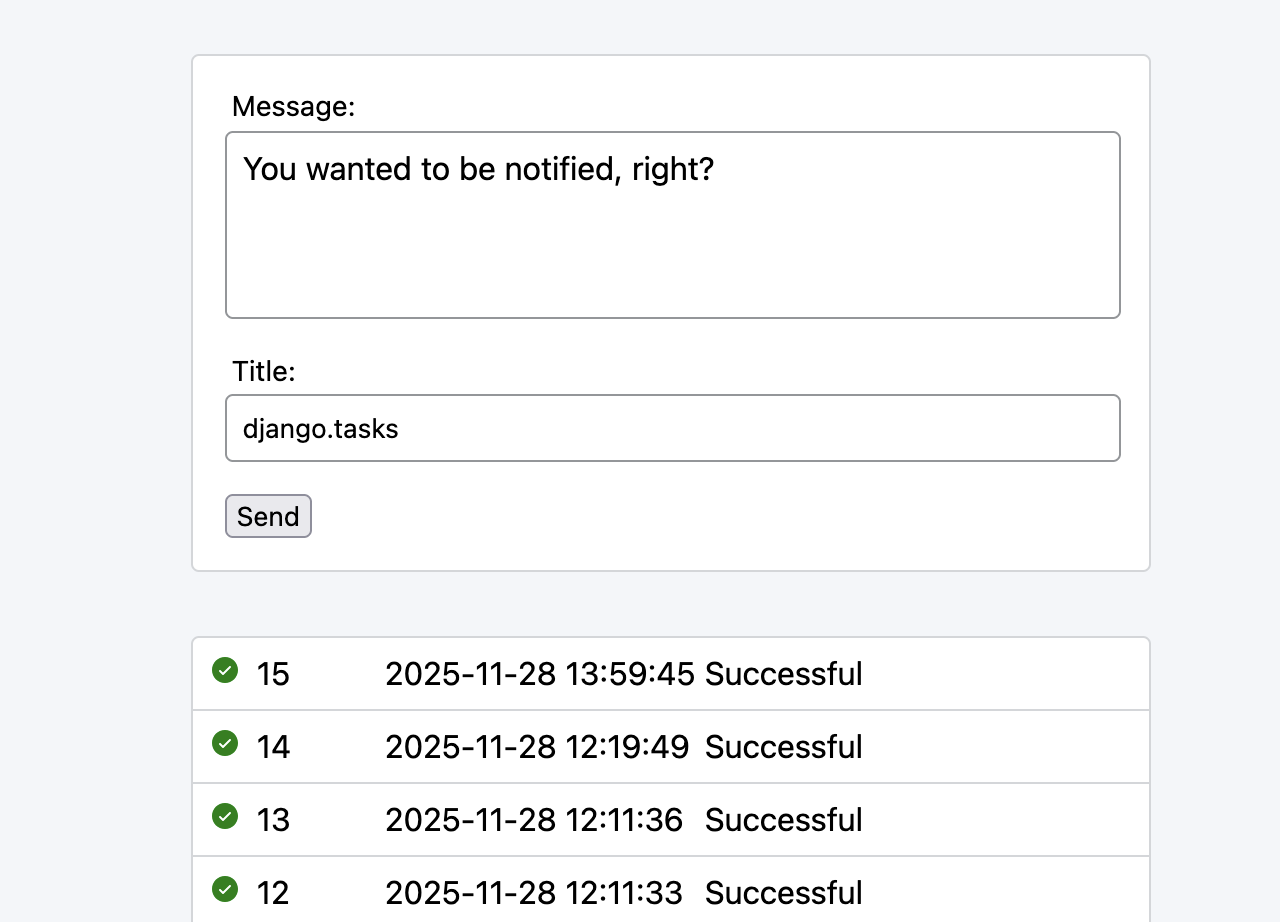
The list underneath the form shows the results for each execution of our task. When the form's submitted, a new result is added to the top of the list. Htmx is instructed to keep polling for changes as long as the result's status isn't FAILED or SUCCESSFUL.
def task_result(request, result_id, status):
result = send_notification.get_result(result_id)
if result.status == status:
# No need to swap the result.
return HttpResponse(status=204)
return TemplateResponse(request, "index.html#result", {"result": result})
Wondering what index.html#results is doing? Django 6.0 also introduces template partials. In this case our view effectively sends a response containing only the template partial named result.
Behind the scenes
When you decorate a callable with task, the configured backend's task_class is used to wrap the callable. The default's django.task.Task.
That class's enqueue method will in turn invoke the configured backend's enqueue method.
Calling its get_result method is similar: call the configured backend's get_result method and pass on the result.
Since there's no workers, that's basically all a task backend needs to provide. Cool. Let's add one, shall we?
A task database backend
Our goals:
- A basic task backend, backed by our database.
- We want to support "automagic" retries
Our enqueue and get_result methods will return an instance of the default django.tasks.TaskResult. This determines the minimum amount of data we need to store, and we're going to do so in a model called Task.
Models
Let's create a first draft of our Task model, based on the properties of TaskResult and Task in django.tasks (the "dataclasses"):
class Task(models.Model):
priority = models.IntegerField(default=0)
callable_path = models.CharField(max_length=255)
backend = models.CharField(max_length=200)
queue_name = models.CharField(max_length=100)
run_after = models.DateTimeField(null=True, blank=True)
takes_context = models.BooleanField(default=False)
# Stores args and kwargs
arguments = models.JSONField(null=True, blank=True)
status = models.CharField(
choices=TaskResultStatus.choices, max_length=10, default=TaskResultStatus.READY
)
enqueued_at = models.DateTimeField()
started_at = models.DateTimeField(blank=True, null=True)
finished_at = models.DateTimeField(blank=True, null=True)
last_attempted_at = models.DateTimeField(blank=True, null=True)
return_value = models.JSONField(null=True, blank=True)
What's missing? For one, the TaskResult also includes a list of encountered errors, and ids of the workers that processed the task. Something that we could perhaps ignore.
Except the TaskResult.attempts property is based on the number of worker ids. And if you're using the task context within a task, you're bound to be relying on that type of information.
We could add these details to the Task model by adding a JSONField for each. This is the current approach in the reference implementation.
But let's be more explicit in our approach and define models for these as well. We'll record each attempt to execute a task and its potential error, linking them to the task with a foreign key:
class Error(models.Model):
exception_class_path = models.TextField()
traceback = models.TextField()
class AttemptResultStatus(TextChoices):
# Subset of TaskResultStatus.
FAILED = TaskResultStatus.FAILED
SUCCESSFUL = TaskResultStatus.SUCCESSFUL
class Attempt(models.Model):
task = models.ForeignKey(Task, related_name="attempts", on_delete=models.CASCADE)
error = models.OneToOneField(
Error, related_name="attempt", on_delete=models.CASCADE, null=True, blank=True
)
worker_id = models.CharField(max_length=MAX_LENGTH_WORKER_ID)
started_at = models.DateTimeField()
stopped_at = models.DateTimeField(blank=True, null=True)
status = models.CharField(
choices=AttemptResultStatus.choices, max_length=10, blank=True
)
This setup ensures we have all necessary information to execute a task, plus we can provide every single bit of detail when a TaskResult is requested.
All fine and dandy, but we need to think about the worker's requirements as well. It needs to be able to:
- Quickly check for outstanding tasks
- Claim one of those tasks
- Process that task and either mark it as failed, successful or ready (to retry later)
We could do all of that with how it's set up right now, but I'd like to refine things a bit.
class Task(models.Model):
# ...
# This field is used to keep track of when to run a task (again).
# run_after remains unchanged after enqueueing.
available_after = models.DateTimeField()
# Denormalized count of attempts.
attempt_count = models.IntegerField(default=0)
# Set when a worker starts processing this task.
worker_id = models.CharField(max_length=MAX_LENGTH_WORKER_ID, blank=True)
# ...
The available_after field will contain the earliest time at which the task can be executed. If the task's run_after is specified (which can be done by using a task's... using() method), available_after is set to that value. Otherwise we're using the current datetime; all in UTC.
Once a task needs to be retried, available_after will be set to the next possible point in time the task can be executed. In other words: we can back off.
The attempt_count field makes querying for available tasks a bit easier. Any tasks with an attempt_count greater than the maximum allowed value can be ignored. Yes, their status should have been set to FAILED which means they should be excluded by default, but we could change the configuration and tweak the maximum number of attempts.
The worker_id field is filled when a worker claims a task. This, among other things, prevents any other workers from picking up the task. Assuming the worker id is unique.
Enqueueing and fetching a result
Enqueueing a task could not be easier: create a Task model instance from the Task dataclass instance, save it, done! Well, at least after turning the end result into a TaskResult.
We use the string version of the model's database id as the id of the result.
Retrieving a result is likewise only a matter of loading the task and its attempts, and turning that into a TaskResult.
Here's a simplified version of our task backend as it stands:
class DatabaseBackend(BaseTaskBackend):
supports_defer = True
supports_async_task = False
supports_get_result = True
supports_priority = True
def enqueue(self, task: Task, args, kwargs):
self.validate_task(task)
model = self.queue_store.enqueue(task, args, kwargs)
task_result = TaskResult(
task=task,
id=str(model.pk),
# ...
# More properties being set
# ...
)
return task_result
def get_result(self, result_id):
return self.model_to_result(
self.queue_store.get(result_id)
)
def model_to_result(self, model: models.Task) -> TaskResult:
...
At lot of functionality is deferred to this queue_store property. Before we dive into that, we'll explain the configuration options for this backend.
Configuration
We want to be able to specify defaults for:
- the maximum number of attempts (retries)
- the backoff factor; i.e. we'll back off using
math.pow(factor, attempts)
These can be customized for each individual queue. So we end up with something like this in our OPTIONS:
TASKS = {
"default": {
"BACKEND": "messagecenter.dbtasks.backend.DatabaseBackend",
"OPTIONS": {
"queues": {
"low_priority": {
"max_attempts": 5,
}
},
"max_attempts": 10,
"backoff_factor": 3,
"purge": {"finished": "10 days", "unfinished": "20 days"},
},
}
}
A task added to the low_priority queue will be attempted up to five times, with a backoff factor of 3. Other tasks will be attempted up to ten times with the same backoff factor.
Queue store
The QueueStore class is a companion of our backend. It's focus is on retrieving and enqueueing tasks, checking for tasks to execute and claiming tasks.
However the main reason it's included is to simplify the worker. As we'll see, the worker gets it's own copy of the queue store, limited to the queues it needs to process.
The worker
The worker's job, at least in this project, is to provide information on outstanding tasks to the runner and to drive the processing of those tasks by the backend. Which means it looks like this:
class Worker:
def __init__(
self,
id_: str | None,
backend_name: str,
only: set[str] | None,
excluding: set[str] | None,
):
# Grab the backend and its queue_store.
self.backend = task_backends[backend_name]
queue_store: QueueStore = self.backend.queue_store
# Limit the queue_store to the select queues.
if only or excluding:
queue_store = queue_store.subset(only=only, excluding=excluding)
self.queue_store = queue_store
# Use or create and id. "Must" be unique.
self.id = (
id_ if id_ else create_id(backend_name, queues=queue_store.queue_names)
)
def has_more(self) -> bool:
return self.queue_store.has_more()
def process(self):
with transaction.atomic():
tm = self.queue_store.claim_first_available(worker_id=self.id)
if tm is not None:
self.backend.process_task(tm)
All we need to do to have a functioning worker runner:
- Create an instance of the worker.
- Ask it if there's tasks to execute using
has_more. - If so: tell it to
processthe first available task. If not: go to 4. - Wait, then return to 2.
That's what our dbtasks_worker command does.
Claiming a task
Our queue store provides a peek method which returns the id of the task in our queues with the most urgency; a combination of available_after, priority and attempt_count.
This lets the runner know whether there's more tasks to process. The next step is to claim one of those tasks. So we call peek again and if it returns a task id, we'll try to claim that particular task.
Here's a more basic, clearer version than the one included in our project's QueueStore:
def claim_first_available(
self, worker_id: str, attempts: int = 3
) -> models.Task | None:
qs = models.Task.filter(
worker_id="",
status=TaskResultStatus.READY,
)
for _ in range(attempts):
task_id = self.peek()
if not task_id:
return None
count = qs.filter(pk=task_id).update(
worker_id=self.id_,
status=TaskResultStatus.RUNNING,
)
if count:
return models.Task.objects.get(pk=task_id)
return None
If the count is zero, we failed to claim the task. Otherwise we retrieve it from the database and can start processing.
The loop is included because we ended up here after trying to claim the task identified by peek. Which apparently has already been picked up by another worker. We might as well make the most of it and try to grab another task from the queue.
Processing the task
And finally the thing that actually does something!
The process_task method of our backend:
- Creates an
Attemptand constructs the currentTaskResult. - Executes the task, capturing anything extending
BaseException, or returning thereturn_valueof the task when everything went according to plan. - Either updates the
Taskmodel, theAttemptand theTaskResultwith the final details of the successful execution, or with details about the failure to do so. - And in the latter case: check if the task can be retried.
Again: if you want to dive into the details, have a look at the repository.
That's it
Of course this demo project leaves out all the things you really need to think hard about. Like signals for the worker. Or database transaction logic. That's not to say it's impossible. Far from it. It just wasn't the goal of this article.
The inclusion of this functionality in Django will certainly allow new libraries or adapters for existing task queues to pop up. And we'll probably soon see some complaints that django.tasks isn't extensive enough.
Because, if you're currently using the more advanced functionality of your task queue, there's probably a few things you're missing in django.tasks.
Complex orchestration
Some task queue libraries, like Celery, provide ways of combining tasks. You can feed the result of one task into another, enqueue tasks for each item in a list, and so on.
It should be clear by now that supporting this kind of orchestration isn't the goal of django.tasks. And I don't mind at all. There's no feasible way of creating a unified API to support this. I've had my share of problems with libraries that do claim to support it.
Retry
As mentioned before, there's currently no way to automatically retry a failed task, unless your backend does the heavy lifting. Like ours does.
Depending on your backend this might be easy enough to handle yourself. For example using a decorator:
def retry(func):
@functools.wraps(func)
def wrapper(context: TaskContext, *args, **kwargs):
try:
return func(context, *args, **kwargs)
except BaseException as e:
result = context.task_result
backoff = math.pow(2, result.attempts)
run_after = datetime.now(tz=UTC) + timedelta(seconds=backoff)
result.task.using(run_after=run_after).enqueue(*args, **kwargs)
raise e
return wrapper
@task(takes_context=True)
@retry
def send_email(context: TaskContext, to: str, subject: str, body: str):
# Do your thing
...
An actual worker mechanism
True. But the reference implementation does provide actual workers. Be patient, or even better: start helping out!
There is no perfect solution
I reckon django.tasks will soon result in covering at least the most common 80% of use cases. Yes, its API is simple and limited, but to me that's more a benefit rather than a fault. I think this is as close as you can get to a standardized approach.